Getting Random Values in C and C++ with Rand
At some point in any programmer's life, he or she must learn how to get a random value, or values, in their program. To some this seems involved, difficult, or even beyond their personal ability. This, however, is simply not the case.
Randomizing of values is, at its most basic form, one of the easier things a programmer can do with the C++ language. I have created this short tutorial for Cprogramming.com to aid you in learning, constructing, and using the functions available to you to randomize values.
I will first start with an introduction to the idea of randomizing values, followed by a simple example program that will output three random values. Once a secure understanding of these concepts is in place (hopefully it will be), I will include a short program that uses a range of values from which the random values can be taken.
Ok, now that you know why this tutorial was written, and what it includes, you are ready to learn how to randomize values! So without further ado, let's get started, shall we?
Many programs that you will write require the use of random numbers. For example, a game such as backgammon requires a roll of two dice on each move. Since there are 6 numbers on each die, you could calculate each roll by finding a random number from 1 to 6 for each die.
To make this task a little easier, C++ provides us with a library function, called rand that returns an integer between 0 and RAND_MAX. Let's take a break to explain what RAND_MAX is. RAND_MAX is a compiler-dependent constant, and it is inclusive. Inclusive means that the value of RAND_MAX is included in the range of values. The function, rand, and the constant, RAND_MAX, are included in the library header file stdlib.h.
The number returned by function rand is dependent on the initial value, called a seed that remains the same for each run of a program. This means that the sequence of random numbers that is generated by the program will be exactly the same on each run of the program.
How do you solve this problem you ask? Well I'll tell you! To help us combat this problem we will use another function, srand(seed), which is also declared in the stdlib.h header file. This function allows an application to specify the initial value used by rand at program startup.
Using this method of randomization, the program will use a different seed value on every run, causing a different set of random values every run, which is what we want in this case. The problem posed to us now, of course, is how to get an arbitrary seed value. Forcing the user or programmer to enter this value every time the program was run wouldn't be very efficient at all, so we need another way to do it.
So we turn to the perfect source for our always-changing value, the system clock. The C++ data type time_t and the function time, both declared in time.h, can be used to easily retrieve the time on the computers clock.
When converted to an unsigned integer, a positive whole number, the program time (at execution of program) can make a very nice seed value. This works nicely because no two program executions will occur at the same instant of the computers clock.
As promised, here is a very basic example program. The following code was written in Visual C++ 6.0, but should compile fine on most computers (given u have a compiler, which if your reading this I assume you do). The program outputs three random values.
/*Steven Billington
January 17, 2003
Ranexample.cpp
Program displays three random integers.
*/
/*
Header: iostream
Reason: Input/Output stream
Header: cstdlib
Reason: For functions rand and srand
Header: time.h
Reason: For function time, and for data type time_t
*/
#include
#include
#include
using namespace std;
int main()
{
/*
Declare variable to hold seconds on clock.
*/
time_t seconds;
/*
Get value from system clock and
place in seconds variable.
*/
time(&seconds);
/*
Convert seconds to a unsigned
integer.
*/
srand((unsigned int) seconds);
/*
Output random values.
*/
cout<< rand() << endl;
cout<< rand() << endl;
cout<< rand() << endl;
return 0;
}
Users of a random number generator might wish to have a narrower or a wider range of numbers than provided by the rand function. Ideally, to solve this problem a user would specify the range with integer values representing the lower and the upper bounds. To understand how we might accomplish this with the rand function, consider how to generate a number between 0 and an arbitrary upper bound, referred to as high, inclusive.
For any two integers, say a and b, a % b is between 0 and b - 1, inclusive. With this in mind, the expression rand() % high + 1 would generate a number between 1 and high, inclusive, where high is less than or equal to RAND_MAX, a constant defined by the compiler. To place a lower bound in replacement of 1 on that result, we can have the program generate a random number between 0 and (high - low + 1) + low.
/*
Steven Billington
January 17, 2003
exDice.cpp
Program rolls two dice with random
results.
*/
/*
Header: iostream
Reason: Input/Output stream
Header: stdlib
Reason: For functions rand and srand
Header: time.h
Reason: For function time, and for data type time_t
*/
#include
#include
#include
/*
These constants define our upper
and our lower bounds. The random numbers
will always be between 1 and 6, inclusive.
*/
const int LOW = 1;
const int HIGH = 6;
using namespace std;
int main()
{
/*
Variables to hold random values
for the first and the second die on
each roll.
*/
int first_die, sec_die;
/*
Declare variable to hold seconds on clock.
*/
time_t seconds;
/*
Get value from system clock and
place in seconds variable.
*/
time(&seconds);
/*
Convert seconds to a unsigned
integer.
*/
srand((unsigned int) seconds);
/*
Get first and second random numbers.
*/
first_die = rand() % (HIGH - LOW + 1) + LOW;
sec_die = rand() % (HIGH - LOW + 1) + LOW;
/*
Output first roll results.
*/
cout<< "Your roll is (" << first_die << ", "
<< sec_die << "}" << endl << endl;
/*
Get two new random values.
*/
first_die = rand() % (HIGH - LOW + 1) + LOW;
sec_die = rand() % (HIGH - LOW + 1) + LOW;
/*
Output second roll results.
*/
cout<< "My roll is (" << first_die << ", "
<< sec_die << "}" << endl << endl;
return 0;
}
Templates and Template Classes in C++
Templates are a way of making your classes more abstract by letting you define the behavior of the class without actually knowing what datatype will be handled by the operations of the class. In essence, this is what is known as generic programming; this term is a useful way to think about templates because it helps remind the programmer that a templated class does not depend on the datatype (or types) it deals with. To a large degree, a templated class is more focused on the algorithmic thought rather than the specific nuances of a single datatype. Templates can be used in conjunction with abstract datatypes in order to allow them to handle any type of data. For example, you could make a templated stack class that can handle a stack of any datatype, rather than having to create a stack class for every different datatype for which you want the stack to function. The ability to have a single class that can handle several different datatypes means the code is easier to maintain, and it makes classes more reusable.
The basic syntax for declaring a templated class is as follows:
templateclass a_class {...};
The keyword 'class' above simply means that the identifier a_type will stand for a datatype. NB: a_type is not a keyword; it is an identifier that during the execution of the program will represent a single datatype.
Usually when writing code it is easiest to precede from concrete to abstract; therefore, it is easier to write a class for a specific datatype and then proceed to a templated - generic - class. For that brevity is the soul of wit, this example will be brief and therefore of little practical application.
We will define the first class to act only on integers.
class calc
{
public:
int multiply(int x, int y);
int add(int x, int y);
};
int calc::multiply(int x, int y)
{
return x*y;
}
int calc::add(int x, int y)
{
return x+y;
}
We now have a perfectly harmless little class that functions perfectly well for integers; but what if we decided we wanted a generic class that would work equally well for floating point numbers? We would use a template.
templateclass calc
{
public:
A_Type multiply(A_Type x, A_Type y);
A_Type add(A_Type x, A_Type y);
};
templateA_Type calc ::multiply(A_Type x,A_Type y)
{
return x*y;
}
templateA_Type calc ::add(A_Type x, A_Type y)
{
return x+y;
}
To understand the templated class, just think about replacing the identifier A_Type everywhere it appears, except as part of the template or class definition, with the keyword int.
Game Programming-Creating a Playable Game
By the end of this article we will have a "playable" version of the SameGame. I have playable in quotes because we will have the game in a state the will allow the player to click to remove blocks and end the game when there are no more valid moves left. The game won't be very feature-rich but will be playable. In the remaining articles we'll add more features to increase the difficulty and allow the game to be customized a little.
Event Driven Programming
Event driven programming, if you've never done it before, is a complete paradigm change in programming. If this isn't your first encounter with event driven programming then go ahead and skip to the next section.
Up till now you've probably only written procedural programs in C++. The difference between the two types of programming paradigms is that the flow of control in event driven programming is determined by events not a predetermined set of steps. It is a reactive program. The user does something like click on a button and the program reacts to that event by executing some code. The main loop in an event driven program simply waits for an event to happen then calls the appropriate event handler and goes back to wait for another event. An event handler is a piece of code that is called each time a specific event happens.
Mouse Clicks
The MFC library is inherently event driven and therefore makes it pretty easy for us to create event handlers and respond to any event that we want. To set up event handling in MFC, Visual Studio lists all of the messages that are available to respond to. In this case messages are synonymous with events. All of the Windows messages are constants that start with WM_ followed by the message name. To respond to mouse clicks in the client area of the view there are messages for the left, right and middle mouse buttons. The event that we will use is the WM_LBUTTONDOWN. This message is sent by the MFC framework every time the user clicks the left mouse button down. All we need to do is set up an event handler to listen for this message to be sent and then respond. To add an event handler open up the Properties Window from the CSameGameView header file. Do this by pressing Alt+Enter or from the menu View->Other Windows->Properties Window. Below is what you'll see in the properties window. (If it isn't, make sure your cursor is placed within the class declaration inside the SameGameView.h file.)
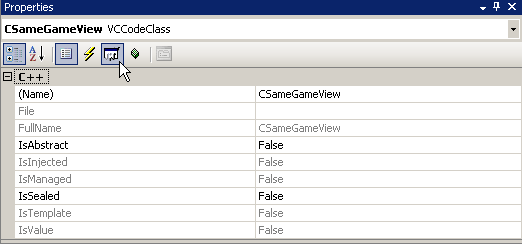
In the screenshot my cursor is hovering over the "Messages" section, click on it. Look for the WM_LBUTTONDOWN option, click on it, click the dropdown as shown in the screenshot below and select "
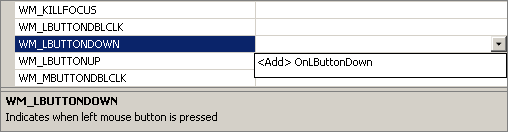
This will add the OnLButtonDown event handler to your view with some default code in it to call the CView implementation of the function. Here we'll add the following code to the function body (changes in bold) Note that this code won't yet compile, but we'll get to that shortly. That's OK to do—the code won't compile, but it lets us figure out what needs to be done to make this function work, without worrying yet about how to write the other functions we will rely on.
Please do wait to compile the resulting code until you've finished the article, since the changes will cascade; as we go through how to implement each of the functions we need, we'll discover we need more functions. But eventually we'll get through all of them.
void CSameGameView::OnLButtonDown(UINT nFlags, CPoint point)
{
// First get a pointer to the document
CSameGameDoc* pDoc = GetDocument();
ASSERT_VALID(pDoc);
if(!pDoc)
return;
// Get the row and column of the block that was clicked on
int row = point.y / pDoc->GetHeight();
int col = point.x / pDoc->GetWidth();
// Delete the blocks from the document
int count = pDoc->DeleteBlocks(row, col);
// Check if there were any blocks deleted
if(count > 0)
{
// Force the view to redraw
Invalidate();
UpdateWindow();
// Check if the game is over
if(pDoc->IsGameOver())
{
// Get the count remaining
int remaining = pDoc->GetRemainingCount();
CString message;
message.Format(_T("No more moves left\nBlocks remaining: %d"),
remaining);
// Display the results to the user
MessageBox(message, _T("Game Over"), MB_OK | MB_ICONINFORMATION);
}
}
// Default OnLButtonDown
CView::OnLButtonDown(nFlags, point);
}
The two arguments to the function are an integer of bit-flags which can be ignored and a CPoint object. The CPoint object contains the (x, y) coordinate of where the mouse was clicked within your view. We'll use this to figure out which block they clicked. The first few lines of code are familiar to us by now; we are just getting a valid pointer to the document. To find the row and column of the block that was clicked we use some simple integer math and divide the x coordinate by the width of a block and the y by the height.
// Get the row and column of the block that was clicked on
int row = point.y / pDoc->GetHeight();
int col = point.x / pDoc->GetWidth();
Since we are using integer division the result is the exact row and column the user clicked on.
Once we have the row and column we will call a function, DeleteBlocks (we'll add it next) on the document to delete the adjacent blocks. This function will return the number of blocks that it deleted. If none are deleted then the function essentially ends. If there were blocks deleted then we need to force the view to redraw itself now that we've changed the game board. The function call Invalidate() signals to the view that the whole client area needs to be redrawn and UpdateWindow() does that redraw.
int count = pDoc->DeleteBlocks(row, col);
// Check if there were any blocks deleted
if(count > 0)
{
// Force the view to redraw
Invalidate();
UpdateWindow();
// ...
}
}
Now that the board has been updated and redrawn we test if the game is over. In the section entitled "Finishing Condition" we'll go over exactly how we can tell if the game is over. For now we'll just add a call to it.
if(pDoc->IsGameOver())
{
// Get the count remaining
int remaining = pDoc->GetRemainingCount();
CString message;
message.Format(_T("No more moves left\nBlocks remaining: %d"),
remaining);
// Display the results to the user
MessageBox(message, _T("Game Over"), MB_OK | MB_ICONINFORMATION);
}
If the game is over we get the number of blocks remaining on the board and report that to the user. We create a CString object which is MFC's string class and call its built-in format method. The format method behaves just like sprintf(). Here we use the MFC _T() macro to allow for different kinds of strings (i.e. ASCII or wide character formats). We finally call the MessageBox() function that displays a small dialog with the title "Game Over" and the message that we created using the format method. The dialog has an OK button (MB_OK) and an information icon (MB_ICONINFORMATION).
Now that this event handler is in place we need to implement the three functions on the document that we called, IsGameOver, DeleteBlocks and GetRemainingCount. These functions are just simple wrappers for the same functions on the game board. So they can just be added to the header file for the document just after the DeleteBoard function, like the following.
bool IsGameOver() { return m_board.IsGameOver(); }
int DeleteBlocks(int row, int col)
{ return m_board.DeleteBlocks(row, col); }
int GetRemainingCount()
{ return m_board.GetRemainingCount(); }
Once we have added these wrapper functions to the document it is time to modify the game board to take care of these operations. In the header file for the game board add the following public methods (again put them right below the DeleteBoard function).
/* Is the game over? */
bool IsGameOver(void) const;
/* Get the number of blocks remaining */
int GetRemainingCount(void) const { return m_nRemaining; }
/* Function to delete all adjacent blocks */
int DeleteBlocks(int row, int col);
Two of the functions are fairly complex and will require quite a bit of code but the GetRemainingCount function simply returns the count of remaining blocks. We'll store that count a member variable called m_nRemaining. We need to add this to the game board in the private member section of the class.
/* Number of blocks remaining */
int m_nRemaining;
Since we are adding another data member to our class we need to initialize it in the constructor like so (changes bolded).
CSameGameBoard::CSameGameBoard(void)
: m_arrBoard(NULL),
m_nColumns(15), m_nRows(15),
m_nHeight(35), m_nWidth(35), // <-- don't forget the comma!
m_nRemaining(0)
{
m_arrColors[0] = RGB( 0, 0, 0);
m_arrColors[1] = RGB(255, 0, 0);
m_arrColors[2] = RGB(255,255, 64);
m_arrColors[3] = RGB( 0, 0,255);
// Create and setup the board
SetupBoard();
}
We also need to update the count of remaining blocks in the SetupBoard method (changes bolded):
void CSameGameBoard::SetupBoard(void)
{
// Create the board if needed
if(m_arrBoard == NULL)
CreateBoard();
// Randomly set each square to a color
for(int row = 0; row < m_nRows; row++)
for(int col = 0; col < m_nColumns; col++)
m_arrBoard[row][col] = (rand() % 3) + 1;
// Set the number of spaces remaining
m_nRemaining = m_nRows * m_nColumns;
}
Deleting blocks from the board is a two step process. First we change all of the same colored, adjacent blocks to the background color, in essence deleting them, and then we have to move the above blocks down and the blocks to the right, left. We call this compacting the board.
Deleting blocks is a prime candidate for the use of recursion. We'll create a recursive helper function called DeleteNeighborBlocks that is private that will do the bulk of the work of deleting blocks. In the private section of the class right after the CreateBoard() function add the following.
/* Direction enumeration for deleting blocks */
enum Direction
{
DIRECTION_UP,
DIRECTION_DOWN,
DIRECTION_LEFT,
DIRECTION_RIGHT
};
/* Recursive helper function for deleting blocks */
int DeleteNeighborBlocks(int row, int col, int color,
Direction direction);
/* Function to compact the board after blocks are eliminated */
void CompactBoard(void);
Graphic-SDL Tutorials
his tutorial assumes that you have already set up Code::Blocks and the MINGW compiler in Windows. Now, we will add the SDL graphical libraries, which will enable you to write graphical applications. After you've done this, you can check out our tutorial on SDL (in progress).
I will assume you've installed Code::Blocks in C:\Program Files\CodeBlocks. If you've installed it elsewhere, you will need to substitute the path you installed it instead of C:\Program Files\CodeBlocks.
Step 1: Download SDL libraries
* Go here: http://www.libsdl.org/download-1.2.php
* Find the header entitled "Development Libraries"
* Under Win32, choose the option that says (Mingw32) after it. The current one at the time of writing this article is "SDL-devel-1.2.12-mingw32.tar.gz", but there may be a newer version when you try. Click on this and download it to your desktop.
Step 2: Uncompress the downloaded .tar.gz file
If you do not have an application that can decompress this type of file, you can get one here: http://www.7-zip.org/download.html
You will want to uncompress it into its own folder, so that we can manually copy the files we need into the CodeBlocks folder.
Step 3: Copy the files from the uncompressed folder to your CodeBlocks folder
I suggest you start by opening both folders and putting them side by side, with the uncompressed folder on the left.
The left folder should look like this:

The right folder should look like this:

First, double click on the "include" folder in the left window. Move the SDL folder from the left window, into the "include" folder in the right window. When you finish doing this, your right window's include folder should look like:

(It's important that you copy the whole SDL folder, and not just the files inside of it.)
Now, go back to the view you had before you moved the SDL folder.
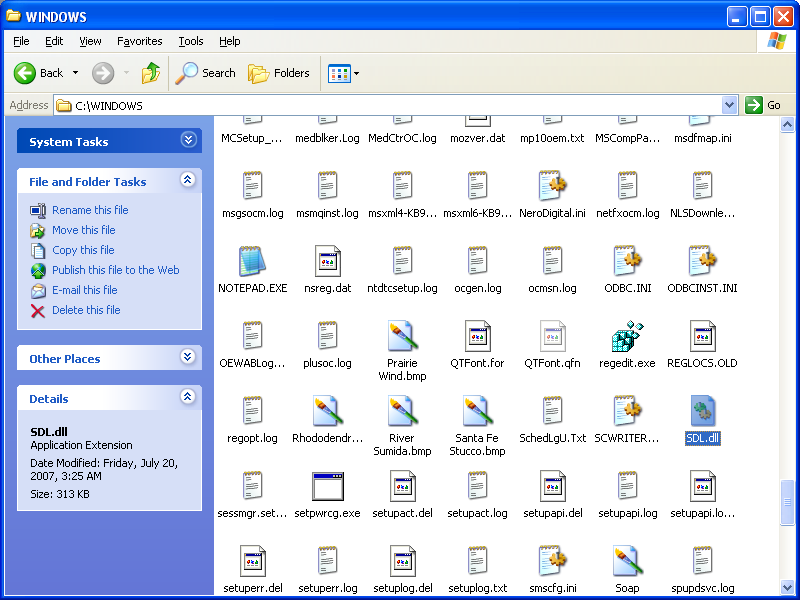
Go to the "bin" folder on the left. Move the SDL.dll file to the "C:\Windows" folder. After you do that, the "C:\Windows\" folder should look somewhat similar to this:
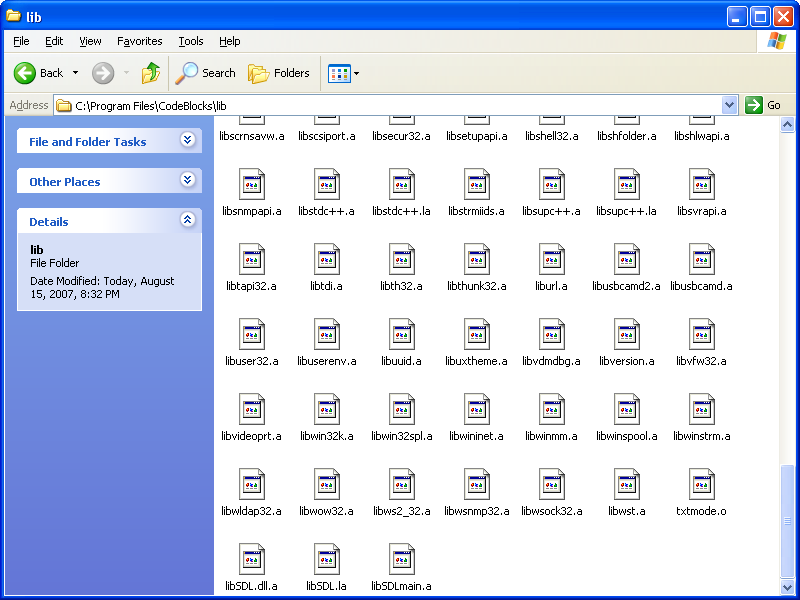
Finally, you'll need to copy the contents of the "lib" folder on the left folder over to the "lib" folder on the right. When you do this step, your right folder should look like this:
Test your installation
Your installation should be done at this point, so you can close the folders, and open up Code::Blocks.
Go to File and then New Project. Choose the SDL Application and hit Create. You will need to select a place to put it--I recommend you put it in its own folder. Open the main.cpp file and hit F9.
If you see compilation warnings, then you probably did not install the "include" folder correctly. If it compiles okay, but crashes complaining about SDL.dll, then you did not install the "bin" folder correctly.
Otherwise, you should see the following window pop up, which means that everything is working!

The Principals of Animation
I am sure all of you have seen a computer game with animation at one or other time. There are a few things that an animation sequence must do in order to give an impression of realism. Firstly, it must move, preferably using different frames to add to the realism (for example, with a man walking you should have different frames with the arms an legs in different positions). Secondly, it must not destroy the background, but restore it after it has passed over it. This sounds obvious enough, but can be very difficult to code when you have no idea of how to go about achieving that. In this trainer I will discuss various methods of meeting these two objectives.
=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
þ Frames and Object Control
It is quite obvious that for most animation to succeed, you must have numerous frames of the object in various poses (such as a man with several frames of him walking). When shown one after the other, these give the impression of natural movement.
So, how do we store these frames? I hear you cry. Well, the obvious method is to store them in arrays. After drawing a frame in Autodesk Animator and saving it as a .CEL, we usually use the following code to load it in :
TYPE icon = Array [1..50,1..50] of byte;
VAR tree : icon;
Procedure LoadCEL (FileName : string; ScrPtr : pointer);
var
Fil : file;
Buf : array [1..1024] of byte;
BlocksRead, Count : word;
begin
assign (Fil, FileName);
reset (Fil, 1);
BlockRead (Fil, Buf, 800); { Read and ignore the 800 byte header }
Count := 0; BlocksRead := $FFFF;
while (not eof (Fil)) and (BlocksRead <> 0) do begin
BlockRead (Fil, mem [seg (ScrPtr^): ofs (ScrPtr^) + Count], 1024, BlocksRead);
Count := Count + 1024;
end;
close (Fil);
end;
BEGIN
Loadcel ('Tree.CEL',addr (tree));
END.
AI-MiniMax Game Trees
The Minimax Game Tree is used for programming computers to play games in which there are two players taking turns to play moves. In the most basic sense, the minimax tree is just a tree of all possible moves. For instance, take a look at the following minimax tree of all the possible first two moves of Tic-Tac-Toe (the tree has been simplified by removing symmetrical positions).
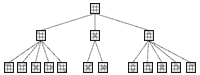
The tree above has three levels, but in programming, the levels of a minimax tree are commonly referred to as plies. At each ply, the opportunity to play (the "turn") switches to the other player. The two different players are usually referred to as Max and Min (this convention will be explained shortly).
With a full minimax tree, the computer could look ahead for each move to determine the best possible move. Of course, as you can see in the example diagram, the tree can get very big with only a few moves, and to look even just five moves ahead can quickly overwhelm a simple computer. Thus, for large games like Chess and Go, computer programs are forced to estimate who is winning or losing by sampling just a small portion of the entire tree. Also, programmers have come up with algorithms such as Alpha-Beta pruning, Negascout, and MTD(f) to try to limit the number of nodes the computer must examine.
The minimax game tree, of course, cannot be used very well for games in which the computer cannot see the possible moves. In poker, for instance, the computer will have a very hard time judging what the opponent will do because the computer can't see the opponent's hand. So, minimax game trees can be used best for games in which both players can see the entire game situation. These kinds of games, such as checkers, Othello, chess, and go, are called games of perfect information.
The reason this data structure is named the minimax game tree is because of the logic behind the structure. Let us assign points to the outcome of a game of Tic-Tac-Toe. If X wins, the game situation is given the point value of 1. If O wins, the game has a point value of -1. Now, X will be trying to maximize the point value, while O will be trying to minimize the point value. So, one of the first researchers on the minimax tree decided to name player X as Max and player O as Min. Thus, the entire data structure came to be called the minimax game tree.
This minimax logic can also be extended to games like chess. In these more complicated games, however, the programs can only look at the part of the minimax tree; often, the programs can't even see the end of the game because it is so far down the tree. So, the computer only look at a certain number of nodes and then stops. Then the computer tries to estimate who is winning and losing in each node, and these estimates result in a numerical point value for that game position. If the computer is playing as Max, the computer will try to maximize the point value of the position, with a win (checkmate) being equal to the largest possible value (positive 1 million, let's say). If the computer is playing as Min, it will obviously try to minimize the point value, with a win being equal to the smallest possible value (negative 1 million, for instance).
AI-Chess board representation
One of the deciding factors in the structure of a board game program is the representation of the board. In Chess AI, the representation of the board has differed quite a lot from program to program, and over time new systems have been invented.
The first system, and the one that may be thought of as the simplest in concept, is just an 8 x 8 matrix that can hold one value per square: 0 if there the square is empty, 1 if there is a white pawn, 2 if there is a white knight, -1 if there is a black pawn, etc.
This concept is really quite easy, because it just requires a matrix and some constants. However, it can become difficult to compute the possible moves on the board, because the computer must check the bounds and the locations of the pieces over and over. So, the program will cycle through the board perhaps 20-30 times per turn.
Another representation method tries to help the computation of moves by combining the normal move generator and the bounds checking mechanism. The hardest moves to compute are those of the knight, for it can leap over and around other pieces, and the moves are not in a straight line or diagonal like all of the other pieces. Also, the knight can jump far outside the board, and it is difficult to compute an illegal move for the knight.
So, this new system proposes to have the board represented not on an 8 x 8 matrix as previously done, but in a 12 x 12 matrix. The 8 x 8 matrix of the board is then centered with a 2 row border around it. This ensures that all knight moves lie within the matrix, no matter where the knight starts from. Next, the program treats the 2 row border as "filled" (that is, occupied by unmovable, undesignated pieces) and thus, the moves into the border by any piece would be illegal. This method tries to integrate the move generator and the bounds checker by creating a raised "rim" around the board, ensuring that any move trying to get out will be blocked by the "rim."
By far one of the most innovative representations is the bitboard. Say you have a 64-bit integer. Now, that's interesting...there are also 64 squares on a chess board...quite a coincidence. Some programmers also recognized this coincidence, and they quickly caught on to how valuable this relationship might be.
A 64-bit integer can be processed by a 64-bit CPU quite easily and quickly, so programmers reasoned that if the chess board could be represented on a 64-bit integer, the CPU would process the application faster and more easily.
Thus, the bitboard -- as it is known -- was born. Each bitboard can only have values of true and false (1's and 0's), so you would have multiple bitboards, and each bitboard would keep track of one aspect of the board position. For instance, one bitboard could keep track of all empty squares, another could keep track of all White rooks, another for all White pawns, another for all Black bishops, and so on. To access one square of a bitboard required only a few bit-operations, which languages like C handled well. The C++ code for accessing a square of the bitboard would look like this:
bool getSquare(bitBoard bb, int squareNum)
{
// Checks to see if the bitboard "bb" has a value of
// true at the bit "squareNum" bits from the right.
return (bb & (1 << squareNum));
}
This representation was overwhelmingly successful, and many of the top chess computers of today use this representation scheme because it optimizes the advantage of the 64-bit processor.
Bitboards are also quite handy for move generation. For instance, let's say you have all of the possible moves for Black's knights computed and recorded on a bitboard. Then, to decide which moves are blocked by Black's own pieces, you take a bitboard of all of Black's pieces, take the complement (the NOT operator) and then AND it to your knights' moves bitboard. The resulting bitboard contains all of the possible moves of Black's knights. Although it takes a bit of work, this method can be applied in similar ways to generate the moves of other pieces as well.
The main reason to use the bitboard over other representations is speed, but there are tradeoffs. Using the bitboard in an quick manner is complicated, and it can take up a lot of space (you have to have many different bitboards to store all the information you need, and it is often quite useful to have many extra kinds of bitboards to speed up certain operations, such as bitboards to record all of the different places the black king could move). So, many programs use one of the previously described representation methods, which are simpler to describe and implement. In the same way as other algorithms, the use of efficient board representations is a tradeoff between complexity, speed, and space requirements.